• Text Generation: RAG can not only retrieve relevant documents but also generate summaries, reports, or document abstracts based on these materials, enhancing the coherence and accuracy of generated content. For example, in the legal domain, RAG can integrate relevant statutes and case law to produce detailed legal opinions, ensuring comprehensiveness and rigor. This is particularly critical in legal consulting and document drafting, helping lawyers and legal professionals improve work efficiency.
◦ Case Study: Retrieval-Augmented Generation in the Legal Domain
▪ Summary:
▪ Background: Traditional large language models (LLMs) excel in general text generation tasks but face limitations when handling complex legal tasks. Legal documents have unique structures and terminology, and standard retrieval evaluation benchmarks often fail to capture domain-specific complexities. To address this gap, LegalBench-RAG aims to provide a dedicated benchmark for evaluating legal document retrieval effectiveness.
▪ Structure of LegalBench-RAG:
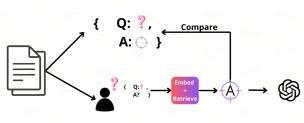
1. Workflow:
a. User Input (Q: ?, A: ?): A user submits a query via an interface, specifying the question requiring an answer.
b. Embedding and Retrieval Module (Embed+Retrieve): Upon receiving the query, the module embeds the question (converting it into vectors) and performs similarity searches in external knowledge bases or documents. Retrieval algorithms identify document fragments or information relevant to the query.
c. Answer Generation (A): Based on the retrieved information, a generative model (e.g., GPT or similar language models) produces a coherent natural language answer.
d. Comparison and Result Return: The generated answer is compared with prior answers to related questions and ultimately returned to the user.
2. The benchmark is built on the LegalBench dataset, comprising 6,858 query-answer pairs traced back to exact locations in original legal documents.
3. LegalBench-RAG focuses on precisely retrieving small, contextually relevant passages from legal texts rather than broad or irrelevant fragments.
4. The dataset covers diverse legal documents (e.g., contracts, privacy policies), ensuring applicability across multiple legal scenarios.
▪ Significance: LegalBench-RAG is the first publicly available benchmark specifically designed for legal retrieval systems. It provides researchers and companies with a standardized framework to compare the effectiveness of different retrieval algorithms, particularly in high-precision legal tasks such as case citation and clause interpretation.
▪ Key Challenges:
1. The generative component of RAG systems relies on retrieved information; incorrect retrieval results may lead to flawed outputs.
2. The length and terminological complexity of legal documents increase the difficulty of retrieval and generation.
▪ Quality Control: The dataset construction process ensures high-quality manual annotations and textual precision, including multiple rounds of human verification when mapping annotation categories and document IDs to specific text fragments.
Other Application Scenarios
RAG can also be applied to multimodal generation scenarios, such as image, audio, and 3D content generation. For example, cross-modal applications like ReMoDiffuse and Make-An-Audio leverage RAG to generate content across data formats. Additionally, in enterprise decision support, RAG enables rapid retrieval of external resources (e.g., industry reports, market data) to generate high-quality, forward-looking reports, enhancing strategic decision-making capabilities.